
For the past two years, Retrieval-Augmented Generation (RAG) has been the default architecture for production AI systems handling large or dynamic datasets. If you were building anything “serious,” you probably had embeddings, a vector database, chunking strategies, rerankers, and a carefully engineered prompt assembly pipeline. RAG became the safe answer to hallucinations and knowledge freshness.
But lately, in real-world projects, I find myself proposing something much simpler far more often: Pure LLM API implementation with structured context injection. No full RAG stack.
Let’s explore this topic further.

Managing Context Window
Modern large language models now support massive context windows. What previously required retrieval pipelines can often fit directly into a single structured prompt.
Instead of building a full pipeline for document chunking, embedding generation, vector database storage, similarity search, reranking, and prompt assembly, we can design a system that relies on deterministic preprocessing, intelligently structured context injection, a single model API call, and schema enforcement through guardrails.
With fewer moving parts, the system achieves lower latency, reduced operational overhead, and higher determinism. By simplifying the architecture and removing unnecessary components, it becomes easier to operate, more predictable in behavior, and faster in execution.
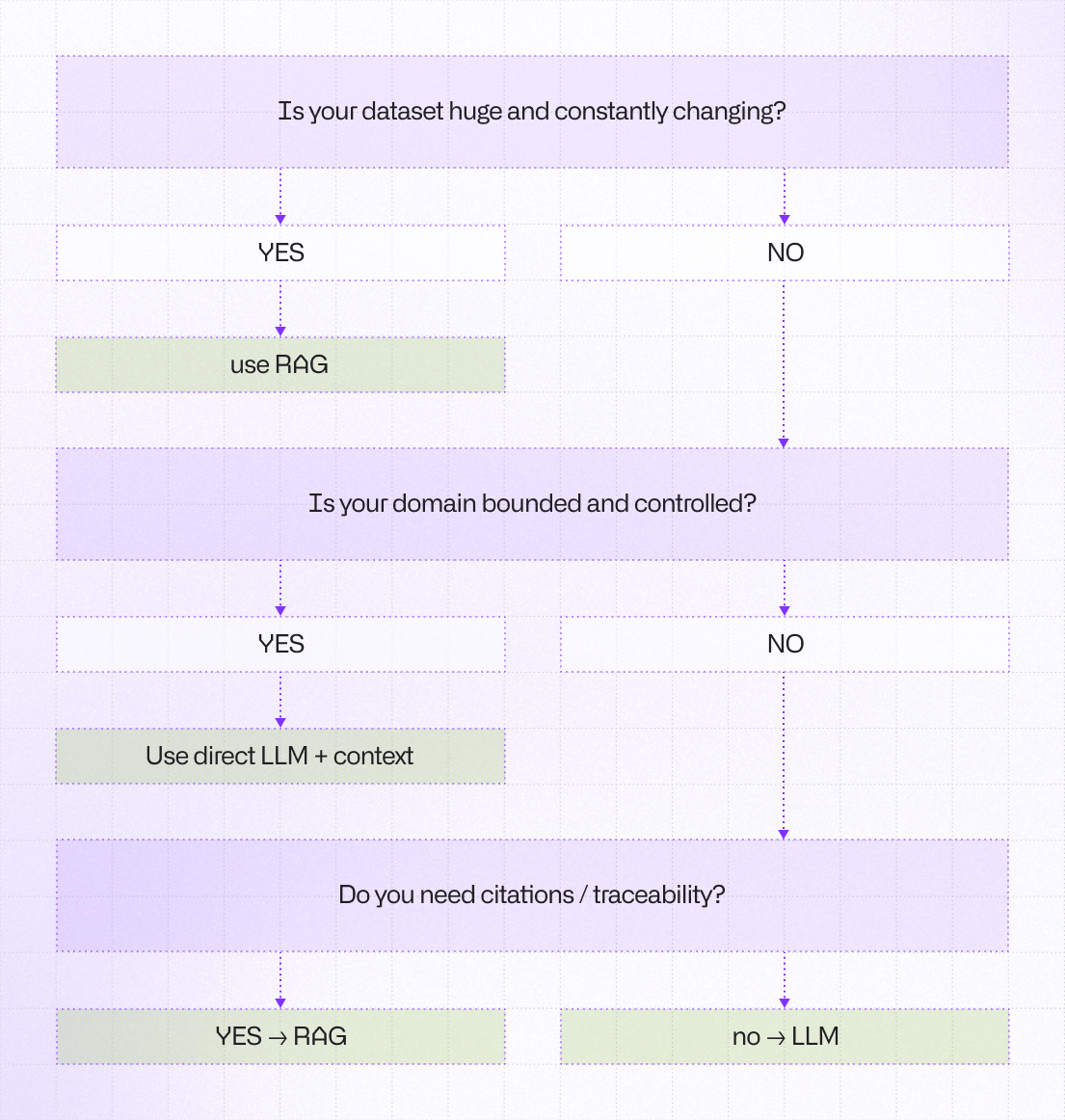
For systems with a bounded scope, controlled data sources, and relatively stable documents, this approach is often good enough to produce positive outcomes.
The Hidden Cost of RAG
Full RAG architecture introduces complexity that teams often underestimate. So, what are the hidden costs of RAG?
Embedding drift when documents evolve
Embeddings are generated from a specific version of a document. When the document changes, the previously generated embeddings may no longer represent the current content accurately. This creates semantic misalignment between stored vectors and the actual data, degrading retrieval quality over time unless embeddings are recomputed.
Re-indexing pipelines
Whenever documents are updated, added, or removed, embeddings must be regenerated and the vector index rebuilt or updated. This requires dedicated ingestion pipelines, background processing, and index management. At scale, re-indexing introduces operational overhead and delays before new information becomes searchable.
Vector database scaling costs
Vector databases must store high-dimensional embeddings and support approximate nearest neighbor (ANN) search. As the corpus grows, storage requirements, memory usage, and query compute increase significantly. Scaling these systems often requires specialized infrastructure, distributed indexing, and expensive memory-optimized nodes.
Chunking strategy inconsistencies
Documents must be split into chunks before embedding, but chunk boundaries are heuristic and task-dependent. Different chunk sizes or overlap strategies can significantly affect retrieval performance. Poor chunking may split important context across segments or include irrelevant information, reducing the effectiveness of similarity search.
Retrieval precision and recall trade-offs
Vector retrieval requires tuning parameters such as top-k results, similarity thresholds, or ANN search settings. Increasing recall may introduce irrelevant chunks, while optimizing for precision may exclude relevant information. Achieving the right balance is task-specific and often requires continuous tuning.
Observability gaps
Similarity-based retrieval often behaves as a black box. It can be difficult to explain why a specific chunk was retrieved for a query because the decision is based on high-dimensional vector similarity. This lack of transparency complicates debugging, auditing, and trust in production AI systems.
In practice it means that RAG systems often fail not because the model is weak, but because retrieval is poorly managed.
The irony is that we built complex pipelines to reduce hallucinations but frequently introduced probabilistic instability at the retrieval layer instead.
Pure LLM and Context
In my professional experience working with clients in the banking industry, we have often achieved better results using a direct LLM API approach combined with careful context engineering, rather than implementing a full retrieval pipeline.
This approach works particularly well for small and manageable knowledge bases, as well as for retrieving information from relatively static document collections. In these scenarios, precision is typically more important than recall, and latency is a critical requirement for production systems.
By simplifying the architecture and injecting intelligently prepared context directly into the model, we were able to reduce system complexity and deliver production solutions faster. In many cases, this simpler architecture proved more reliable and easier to operate than traditional RAG pipelines.
For example, context injection works perfectly with implementation of internal copilots, Policy Q&A assistants, structured document summarization, controlled domain analysis and agent-style workflow orchestration. When context is well-defined, the model behaves more predictably. That predictability matters more than RAG architectural elegance.
When RAG Still Makes Sense
RAG is not obsolete. It remains powerful for systems with large, frequently updated datasets, research-heavy workflows, legal environments requiring citation, and multi-tenant document platforms. In these cases, retrieval is not optional. We should treat RAG as a scaling mechanism.
In production systems, RAG architectures typically rely on vector databases optimized for approximate nearest neighbor (ANN) search. Common systems used in enterprise deployments include, for example, Pinecone, a managed vector infrastructure designed for large-scale semantic search workloads, and Qdrant, a high-performance vector search engine with filtering and payload support. These are the ones I'm highlighting here, as they are the ones I worked with directly.
In my experience working on such systems, these technologies are combined with embedding models and orchestration layers to build scalable RAG pipelines capable of supporting millions or billions of vectors.
From Retrieval to Context Engineering
Modern LLM system design is gradually shifting from heavy retrieval pipelines toward context engineering—the practice of carefully constructing the information and constraints provided to the model at runtime.
Context engineering includes techniques such as schema enforcement, structured system prompts, metadata injection, tool usage constraints, API-level orchestration, and deterministic preprocessing pipelines that prepare relevant information before it reaches the model.
Here’s a simplified example of what structured context injection looks like in practice:
const context = {
userRole: "analyst",
documentSummary: "...preprocessed summary...",
policies: [...relevantPolicies],
constraints: {
outputFormat: "json",
allowedActions: ["summarize", "classify"]
}
};
const response = await openai.responses.create({
model: "gpt-5.1",
input: [
{
role: "system",
content: `You are a financial assistant.
Return output strictly as JSON.`
},
{
role: "user",
content: `
Context:
${JSON.stringify(context, null, 2)}
Task:
Analyze the document and return structured insights.
`
}
]
});Context engineering includes techniques such as:
- Schema enforcement – forcing the model to produce outputs that follow a predefined structured format (e.g., JSON schema), ensuring consistency and machine-readability.
- Structured system prompts – carefully designed system instructions that define the model’s role, rules, and response structure.
- Metadata injection – adding contextual information such as document source, timestamps, user roles, or domain tags to guide the model’s reasoning.
- Tool usage constraints – restricting when and how the model can call external tools or functions to maintain safety and predictable workflows.
- API-level orchestration – coordinating model calls, tool interactions, and validation logic through application code rather than relying on the model alone.
- Deterministic preprocessing pipelines – preparing and structuring relevant information (documents, tables, summaries) before it is passed to the model, ensuring consistent context construction.
Instead of relying on probabilistic retrieval to discover context, the system explicitly defines what the model should see and how it should behave. As models continue to improve in reasoning, instruction following, and structured output generation, architectures should trend toward simplification rather than expansion, reducing infrastructure complexity while increasing determinism, observability, and control over model behavior.
The Takeaway
The next wave of AI systems may not be retrieval-heavy pipelines, but clean API-driven intelligence layers with intentional context injection. Sometimes the most advanced architecture, is the one you decided not to build.



Learn more about AI
Here's everything we published recently on this topic.





















