




Every React Native developer has an opinion about which AI coding model writes the best code. We had opinions too. The problem was that none of us could prove it.
Conversations about model quality in the coding space tend to be anecdotal. Someone tries a model on a navigation task, gets a good result, and declares it the best. Someone else has a bad experience with animations and writes it off. Neither conclusion is reproducible, and neither helps the community make informed decisions.
We built React Native Evals to fill that gap. The goal is simple: make model quality discussions in the React Native ecosystem reproducible and evidence-based.
What is React Native Evals
React Native Evals is a benchmark suite consisting of self-contained implementation tasks that reflect the kind of work React Native developers do every day. Each eval presents a model with a scaffold, a prompt, and a set of requirements. The model generates code. A judge evaluates whether the code meets those requirements.
The project includes:
- A dataset of eval tasks organized by category and library
- A runner pipeline built with TypeScript and Bun that handles generation and judging
- A methodology whitepaper that formally specifies scoring and reproducibility
What we benchmark today
The benchmark currently ships with 43 evals across 3 categories, covering the libraries React Native developers use most:
- Animation - covering
react-native-reanimated,react-native-gesture-handler,react-native-worklets, andreact-native-keyboard-controller. Tasks range from basic timing animations to complex multi-gesture compositions. - Async State - spanning
@tanstack/react-query,zustand,jotai, and React built-in concurrency primitives. These cover the async patterns that cause the most subtle bugs in production. - Navigation - targeting
@react-navigation/native,@react-navigation/native-stack,@react-navigation/bottom-tabs, and@react-navigation/drawer. Tasks cover the navigation scenarios that every production app needs.
What is coming next
We are actively expanding the benchmark. The following categories are in development:
- react-native-apis - Core React Native platform APIs
- expo-sdk - Expo module integration patterns
- expo-router - Dedicated navigation for Expo Router and its most common patterns
- nitro-modules - Native module bridging with Nitro
- lists - Virtualized list performance and behavior
Our goal is to grow the benchmark to cover the breadth of what React Native developers build in practice. If there is a library or pattern you think should be included, open an issue, or better yet, contribute an eval.
Our methodology
The benchmark uses a two-phase pipeline: generation and judging.
In the generation phase, the solver model receives a task prompt and a set of baseline scaffold files. It returns modified files that implement the requested feature. In the judging phase, a separate LLM evaluates the generated code against a structured list of requirements defined in each eval's requirements.yaml.
The full methodology is documented in the whitepaper included in the repository.
Preliminary results
We have started running the benchmark across several widely used coding models to establish a baseline for React Native performance.
The chart below shows the first comparison across models using the current set of evals.
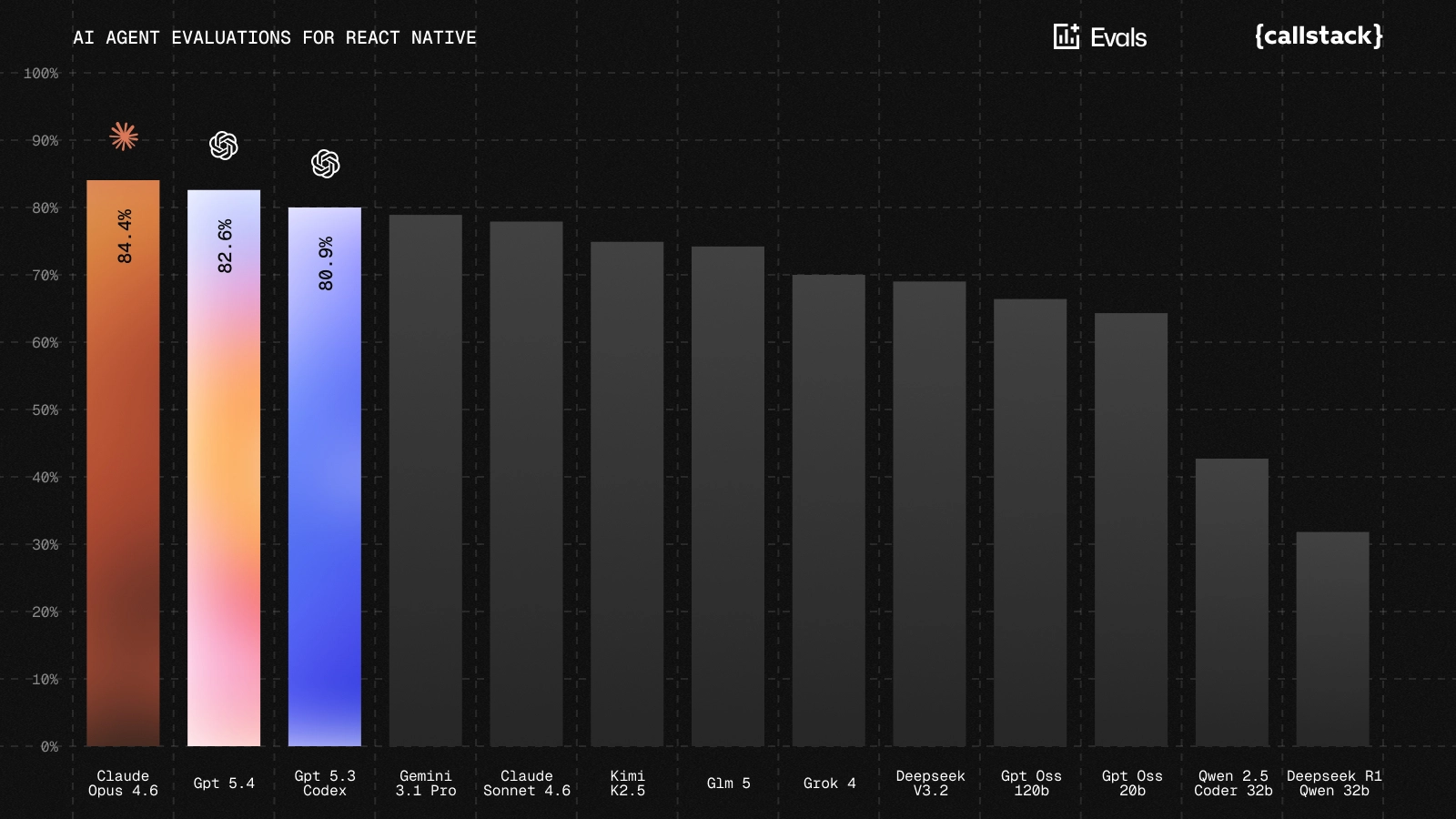
You can also browse the results on the interactive website here.
The benchmark is still evolving, the dataset will continue to grow, and we expect results to change as both models and evaluation methodology improve. Our goal with publishing these early results is not to declare a winner, but to demonstrate that reproducible measurement of React Native coding ability is possible and to invite the community to participate in refining the benchmark.
Check it out
React Native Evals is open source under the MIT license. The repository lives at github.com/callstackincubator/evals. Star it, run it against your preferred model, and let us know what you find.
Contributions (new evals, new categories, methodology improvements) are welcome. We think the React Native ecosystem deserves the same rigor in model evaluation that the broader software engineering community is building. This is our contribution to getting there.

Learn more about AI
Here's everything we published recently on this topic.





















