
For the past month, I've been thinking about many different strategies for agentic model cooperation. That includes different vendors, infrastructure choices, and model setups, from one model to several models working together on a single issue or project.
I constantly observe market trends and major global AI labs, looking not only at new model releases and tips for conquering the world with AI, but also at infrastructure. I found something really interesting right after the AI Engineers conference in Miami. After dozens of discussions, it became clear to me: the quiet, rising new trend is agentic swarms.
For example, Cloudflare shared a plan with me (not yet public) to build an infrastructure mesh system for distributed inferencing. Many agents, many outputs. Automatically scaled serverless infrastructure and talks about "Agencies" during the conference confirmed my suspicions. The world is preparing not just for super-powerful single models, but for swarms of sufficiently intelligent models dedicated to a single user.
Going deeper, I tried to estimate how many models in a swarm the leading AI labs have already tested. 10k? 100k? Or maybe none of these. It's hard to say what resources they have in their R&D centers and what possibilities they have for experimentation. However, the laws of physics clearly point toward emergent behaviors.
Guess what? I started experimenting with my own agentic swarm!
How many small Gemmas can a single DGX Spark serve?
I decided to build my own swarm to test how many models I could fit onto a single DGX Spark (128GB VRAM) and run inference with them confidently, ensuring nothing gets stuck.
I chose the smallest Gemma models (gemma-3-270m and gemma-3-1b-it) as my swarm species and built a full experimental setup.
Before the numbers, one important distinction. There are two different ways to benchmark this.
- The first is request-level concurrency: many HTTP clients hitting one Ollama daemon serving one model. This mostly tests Ollama’s request scheduler. Memory does not scale much because only one copy of the model is loaded.
- The second is process-level concurrency: every worker gets its own Ollama daemon on a different port, and every daemon loads its own model process. This is the version I cared about, because it answers the real swarm question: how many independent model workers can one machine carry?
For this experiment, swarm-bench spawned N FastAPI workers. Each worker sent requests to its own dedicated Ollama daemon. Every daemon used OLLAMA_NUM_PARALLEL=1, so Ollama’s internal parallel scheduler would not distort the result.
The sweep was simple:
- Workers: 1, 2, 4, 8, 16, 32, 48, 64
- Prompts per worker: 25
- Concurrent requests per worker: 1
- Max tokens: 128
- Temperature: 0.2
- Top-p: 0.9
I classified a run as interactive when p95 first-token latency stayed under 2 seconds and median throughput stayed above 20 tokens per second.
Checking the results
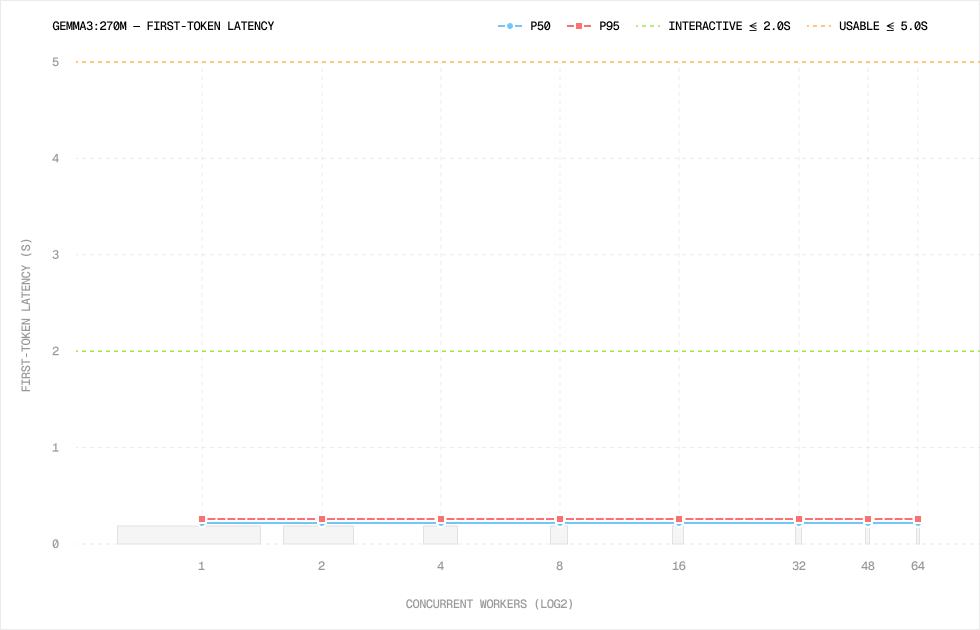
Per-run: gemma3:270m
This was the first surprise.
The 270m model stayed almost perfectly flat from 1 to 64 workers. First-token p95 sat at 0.13s across the whole sweep.
Median throughput stayed around 420 tokens per second per request.
At 64 workers, that gives roughly 27,400 aggregate decode tokens per second.
That does not mean the system was perfect. The minimum TPS started falling after 16 workers, from 330 TPS down to around 46–48 TPS at 48–64 workers.
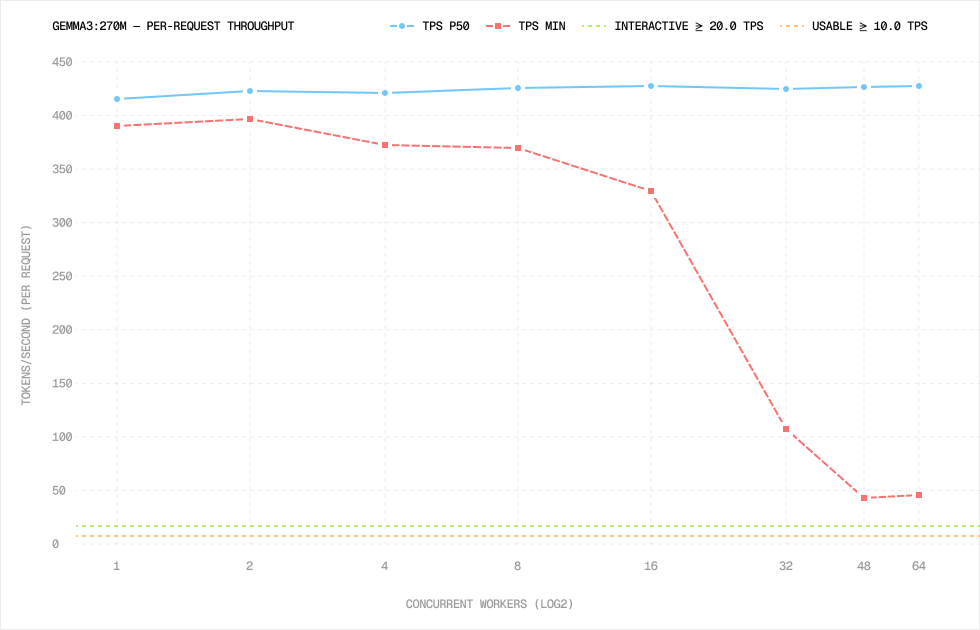
So the median still looked beautiful, but the tail was already getting noisy.
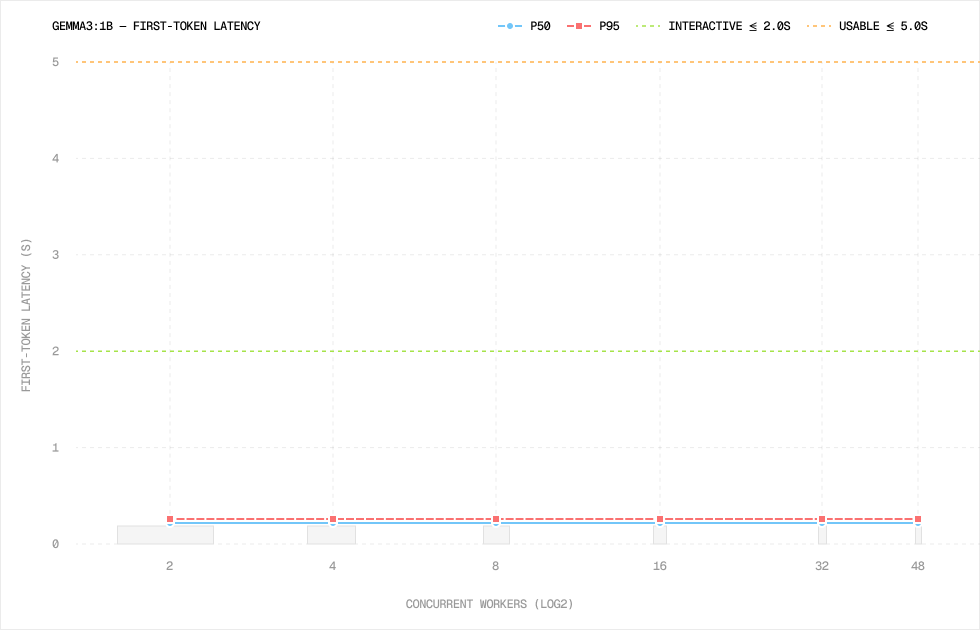
Per-run: gemma3:1b
Gemma 3 1B also held up better than I expected.
Ignoring the failed socket cases, first-token latency stayed around 0.23-0.24s from 2 to 48 workers.
Median throughput stayed between 184 and 195 tokens per second per request.
At 48 workers, that gives roughly 9,350 aggregate decode tokens per second.
There were some strange failures at n=1, n=4, and n=48. The daemon logs showed no traffic for those cases, so this looks more like a FastAPI proxy/socket issue than model saturation. I do not know the root cause yet. The clean results from 2 to 32 workers are consistent enough that I would not treat those failures as the performance limit.
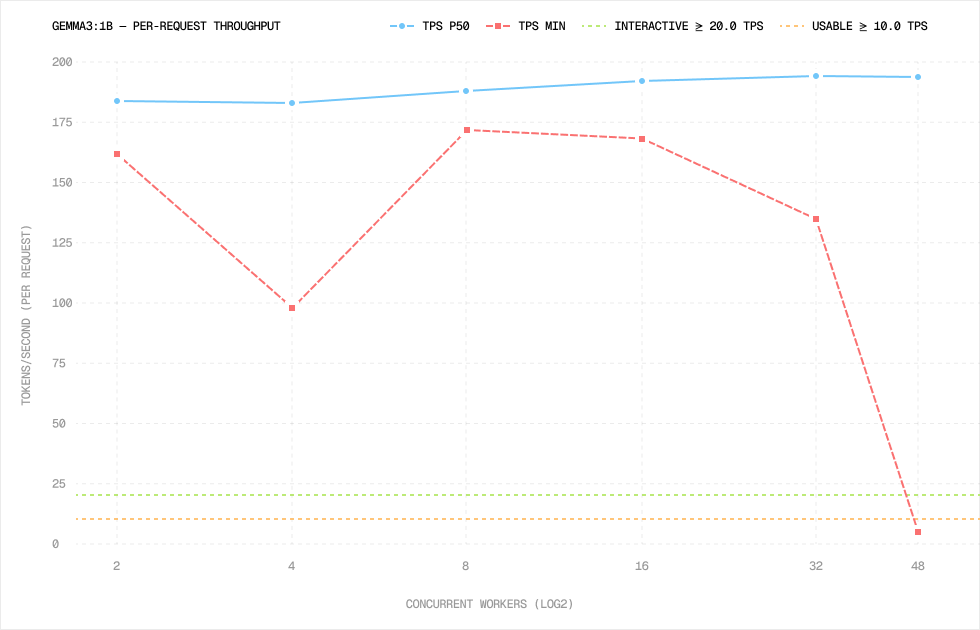
The warning sign appears in the tail again. At 48 workers, minimum TPS dropped to 5.1. So the system still looks strong on median numbers, but individual requests can start behaving badly under heavier load.
One caveat: memory reporting on DGX Spark
This machine uses unified memory, so GPU memory and system memory are not as cleanly separated as they are on a typical desktop GPU. NVML still reports memory.used, but that number should not be read as, "This is exactly how much memory the models used."
There is another wrinkle. Ollama loads GGUF model files through memory mapping. When several daemons use the same model file, the operating system can share some read-only pages between them instead of copying everything N times. So memory does not always grow in a simple straight line as more workers are added.
That is why I treat NVML as a rough trend signal, not an exact footprint.
The rss_peak_mb number is also incomplete in this benchmark. Right now, it only sums the FastAPI proxy workers. It does not include the Ollama daemon processes that hold the model weights. So RSS is useful for spotting worker growth, but it is not the full memory cost of the swarm.
What this proves
I wanted to see whether one DGX Spark could run a real swarm of small models and keep them responsive. It can.
In this sweep, Gemma 3 270m stayed interactive at 64 independent workers, reaching roughly 27,400 aggregate decode tokens per second. Gemma 3 1B stayed interactive at 48 independent workers, reaching roughly 9,350 aggregate decode tokens per second. First-token latency stayed almost flat across the tested range.
That gives me a verified starting point for real agentic work. A swarm is not useful just because many models are running. It becomes useful when those workers can split the job: one model inspecting logs, another checking a failing test, another writing a patch, another reviewing it, another watching state.
Maybe the future is not only one super-powerful model sitting in the middle of everything. Maybe the next jump comes from enough smaller models working together, sharing context, checking each other, and moving as one system. That is the part I want to explore next.



Learn more about AI
Here's everything we published recently on this topic.





















