
Ok, finally the third part arrived.
Read Part 1 Profiling React Native Internals with Tracy for Peak Performance and Part 2 Multithreading Isn’t Free: Performance Pitfalls Visualized.
If you're using React Native, you've probably already heard the term "fiber". In React parlance, this is how the core team called their new reconciliation engine introduced in React 16. Incremental rendering and the ability to suspend rendering are some of its most important features.
But the term "fiber" isn't as arbitrary as it might seem. Let's start our journey with coroutines.
What are coroutines?
Maybe you're old enough to remember a thing called "subroutine" or, perhaps, you're still writing code that uses sub and end sub. You can think of subroutines as functions that don't return anything. They're just an ordered sequence of instructions (side-effects) that can be invoked by their name.
We're so used to today's computing model. Our computers (phones included) are multitasking machines. But back in the day, we had single-core processors, and we were still able to run multiple programs at once. Well, sort of... We were tricked into thinking that those programs run "at the same time," when, in reality, they were "multitasking" like crazy, switching between tasks hundreds if not thousands of times per second.
There are two ways in which this illusion can be achieved:
- The operating system is giving every process the same quanta and switches the running processes;
- Programs themselves are voluntarily giving up their time for other tasks to run.
The former method is "preemptive multitasking", and the latter is "cooperative multitasking".
So, how does this relate to today's topic? Well, coroutines are the perfect tool for implementing such cooperative scheduling! Just think of it as a subroutine (or function) that can be suspended at any time ("yield") and resumed from the same point. In some languages, like Lua or Python, those are also able to pass values this way. (Fun fact: This is how I was able to emulate JavaScript's async/await in Lua!)
What’s so special about it? In short, the coroutines have way less overhead. Each time the OS switches between tasks (processes), it has to do some additional bookkeeping and maintenance; this is called "context switch". When using threads (or multiprocessing), such context switch can happen only in privileged mode (Ring 0) where the operating system's kernel operates. So, our program needs to escalate to kernel using a system call, and this also takes time (adds latency).
Here's the bummer: coroutines can be switched entirely in user mode, and the operating system might not even notice! We just swap out some CPU registers (of course backing up the previous ones) and we are done. Which registers? Well, that depends on the architecture, but most ABIs specify which ones are non-volatile, so a few lines of assembly are all you need.
The coroutines we will be talking about are stackful and symmetric. Simply put, stackful means that each coroutine has its own stack and therefore can be suspended from anywhere, including nested stack frames. Symmetric means that all of them are equal and when "yielding" (switching) we specify to whom we are giving our CPU time.
This, ladies and gentlemen, is why "Fibers" in React is actually not a bad name.
What about fibers, then?
In this context, "fiber" is just a "user-space thread". Just as a single computer can run multiple processes, a single process can run multiple threads, and a single thread can run multiple fibers.
In practice, when we take coroutines and build a scheduler around them, with some synchronization mechanisms, we get fibers.
Our goal is to minimize both wait time and context-switch overhead. In the last article, we saw a really sloppy work-to-wait ratio due to thread contention. By fixing the "global mutex" issue and using fibers to "taskify" everything, we can squeeze out even more performance.
Not so fast...
There’s no silver bullet. And if you're not careful, it's easy to shoot yourself in the foot! While personally I don't think this is an issue, our fibers MUST NOT block. This means that we cannot use "typical" locks or synchronization primitives, and we cannot call blocking OS functions, which disqualifies I/O among other things. Unless... you are fine with potential deadlocks.
This poses a question: how can we synchronize our fibers? How to wait for some dependency fibers to finish? The answer is atomic counters! When a task finishes, it can decrement an atomic counter that was associated with it. This way, if you have a task that processes, say, 10 items (think map()) and then aggregates the results (think reduce()) we have 11 open tasks in our system. The last task depends on those 10 transformations, and can wait for a counter to become 0, right? We really don't care about the order here.
waitForCounter(counter, 0);What happens here? If the condition is not met, we move the current "fiber" to a wait list, and take a free fiber from a pool and switch to it until this counter arrives at the expected value. Simply beautiful!
If you want, you can easily hide the details a tiny bit (e.g., counter), and just expose a single function, which can "look into" the counter itself:
waitForTask(task); /* reference or an opaque handle */Scheduling tasks
Tasks are the smallest units of work we can schedule. It's nothing more than a function to execute and a user-supplied data argument.
The example above clearly shows that tasks can have dependencies, and therefore can be organized in some sort of (dependency) graph or tree. Atomic counters will "let us know" when our child tasks have finished, which is also very convenient.
WorkItem tasks[11];
/* populate tasks... */
Counter *counter = NULL;
addTasks(tasks, 11, &counter); /* kick start the jobs */Again, feel free to change the surface API. If a more procedural style of building tasks is your thing, then you can have something like:
Task parentTask = scheduler->beginTask();
/* ... */
scheduler->addChild(parentTask, childTask);
/* ... add other children... */
scheduler->endAndKickTask();Whatever works for you. In such a case, just remember to create a task with an additionally bumped counter, that will be decremented to a proper value on endAndKickTask() . You don't want the task to complete until you finish declaring it and all its dependencies, do you?
This is the "core" of what you need:
- a function to add tasks;
- a function to wait for a given task to finish.
Theoretically, you don’t even need a function to wait for all tasks; just make a root task that encompasses everything and wait for it to complete.
But how to live without I/O?
This is why IO monad was introduced. Ok... no more Haskell jokes 😅
The simplest option would be to create a dedicated I/O thread for all blocking functions. By the way, this is also what libuv (which powers Node.js) does on Windows. Just treat them as interrupt handlers, they do what they have to (say, read a file/socket) and then quickly spawn a new task / decrement a counter.
Pinning threads down
Running one thread per core allows us to fully harness the computing power of our CPUs. If we cross the line, then (as mentioned in previous part) we will cause oversubscription, and the OS will have to switch the threads. Not fun.
But unfortunately, we don't live in a perfect world. Other processes, and even the OS itself, can interrupt our threads. Occasionally, a thread might get evicted, triggering a ripple through the system. One simple solution to mitigate this issue is pinning the threads to the physical cores. This is supported by most OSes if you look for "CPU affinity": POSIX, WinAPI and OSX. Unfortunately, it seems that iOS cannot join this gang 😔
Great, but where's the profiling part?
Our friend Tracy does support fibers! We just need to define TRACY_FIBERS project-wise and insert two macros: TracyFiberEnter(name); (which can be called multiple times in a row) and TracyFiberLeave;. Given that we wrote the scheduler from scratch, this (and maintaining the pointer to the name) should be a walk in the park.
I've modeled and implemented my fibers somewhere between Windows API and Orbis SDK, but you don't have to. While the POSIX ucontext API is deprecated, you can always pick Boost.Context if you don't feel comfortable writing assembly.
In my case, all I had to do was to add TracyFiberEnter() to both mtbFiberSwitch() and mtbFiberConvertFromThread() functions, and TracyFiberLeave; at the beginning of my mtbFiberConvertToThread() function.
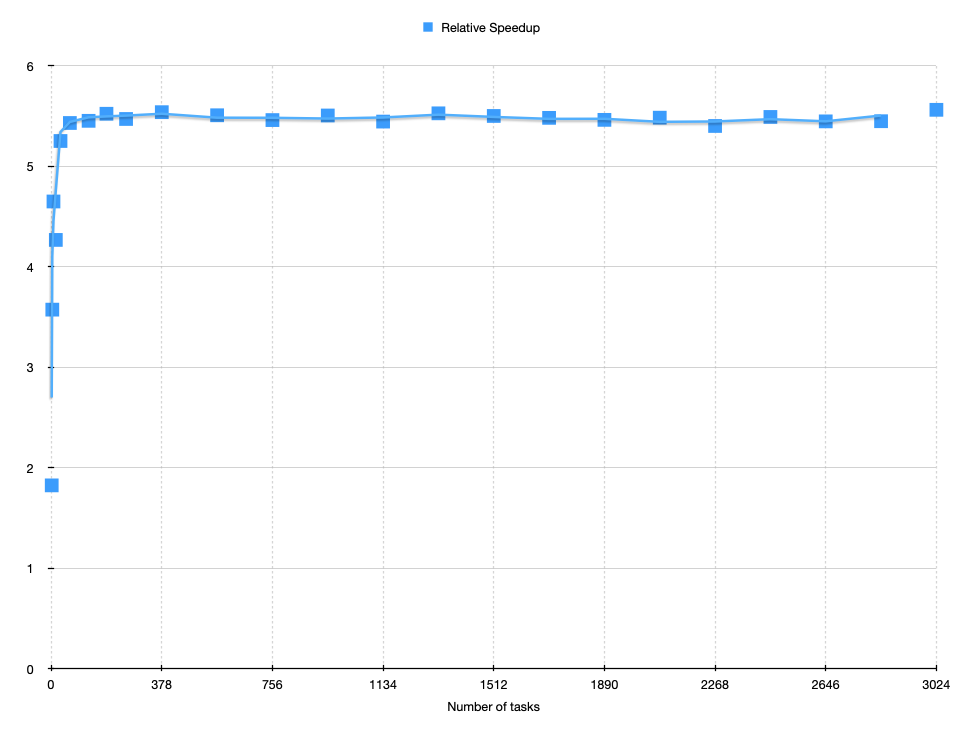
If you do everything correctly, our relative speedup should be more flatlined, no matter the amount of tasks thrown at the problem.
With Tracy, you can also profile the memory usage and, in theory, heap fragmentation. However, those are really specific topics that I’ll not go into here. Feel free to check the official documentation, which covers everything that Tracy can do!
Thank you’s
At the end, I would like to send special thanks to a few people who exposed me to many great ideas regarding multi-threading and lock-free programming:
- Jérôme Muffat-Méridol for his article about Nulstein and Nulstein v2,
- Mike Acton for his insightful post-in notes series,
- Jeff Preshing for his accessible posts on Lock-Free Programming,
- Dmitry Vyukov for his entries on Lockfree algorithms and Scalable Architecture,
- Stefan Reinalter for his amazing blog where he also covered task schedulers,
- both Niklas Gray and Tobias Persson for co-authoring the Bitsquid blog and the Our Machinery blog (mirror),
- Christian Gyrling for his great GDC 2015 talk that showed how cool (and useful) fibers can actually be,
and many, many more souls, that unfortunately I cannot recall. Without their work, I would still be stuck with what was taught at university.
If you want to implement a fiber scheduler yourself, I recommend checking out the 3 last links mentioned above. Christian's talk is one of the best introductions to this topic. I would also recommend watching Dennis Gustafsson's BSC 2025 talk on parallelizing the physics solver. Utilizing an elevated state (dressed in a neat Scope) sounds genuinely intriguing!

Learn more about Performance
Here's everything we published recently on this topic.





















