
Welcome back! In this instalment, I would like to continue my profiling miniseries. As promised at the end of the first part, released in February 2025, we'll focus on multithreaded applications.
“Quiz” answer from Part 1
But before I jump into the topic, let me quickly go back to the last question in the aforementioned article:
PS: One more mystery for you: What else does our original function do besides running the loop? It looks like it spends 70% of its time doing something else… Any clues?
Spoiler alert: This time was spent on allocating and copying memory! I have to admit that I intentionally omitted the & in the function argument list. Indeed, one character has such a huge performance impact. Surprisingly, this is not that uncommon: Meta was able to get estimated 15,000 servers in capacity savings per year just by adding a single & after the auto keyword.
Introduction
Early this year, I had a great opportunity to conduct numerous technical interviews for C++ wizards. I must admit, the process became a bit convoluted as you never know if the other party is using any AI assistants, but that’s a story for a different article. One thing that truly surprised me, though, was how often candidates provided answers that either they didn’t fully believe in or couldn’t defend when I decided to dig a little deeper. Multithreaded programming was one of such areas.
Multithreading is usually the first thing that people mention when they are asked to make their program run faster—assuming, of course, that algorithmic complexity cannot be improved any further. This makes perfect sense, because you can do many things at the same time. Sorry, but in this article I will not get into Instruction-Level Parallelism or Data-Level parallelism (SIMD). Still, I highly encourage everyone to go through this rabbit hole, as they can yield performance improvements ranging from 800% to 3200%!
That said, multithreading is not “free”. It brings a whole set of challenges that you need to take into account. One of them is ensuring proper synchronization to avoid data races. Almost all candidates I interviewed immediately mentioned locks and mutexes as a solution. While that’s a reasonable “default” answer, it’s not the only one! Moreover, locks introduce other issues like starvation, deadlocks, and livelocks.
So, my plan for today’s article is to show you how you can approach profiling a multithreaded application and what to look for during your journey. Straight from the bat, I can provide you with guiding questions for your profiling sessions:
- Are we using the threads effectively?
- Is the work evenly distributed across threads?
- Which threads are waiting on locks?
- How does context switching affect throughput?
While I would love to dive deeper into all these topics, I’m afraid that this blog post would easily turn into a small book—or even a workshop. I’ll try to sneak some references or at least drop some names, so you can research those topics yourself. If you’re interested in a more comprehensive guide, please let me know! 😉
What do you want?
First, you would need to decide what your goal is—this is always the first step when it comes to optimization and profiling. The answer to this question will influence which metrics you would be interested in collecting.
Let’s use an analogy. Imagine that you need to buy a new washing machine and dryer, regardless of the price. Assuming both options would have the same runtime for completing their tasks, would you prefer to buy them separately, or would you opt for a single unit that does both tasks?
As the “execution times” are the same, you might prefer the second option as it might take less space. What if you need to make three rounds of laundry? Obviously, the combo machine will take n × (tw + td) = 3 × 2h = 6h (where n is the number of rounds, tw is washing time and td for drying time), but what if we bought them separately? Here’s where things get interesting.
It would take n × max(td, tw) + min(td, tw) = 3 x 75m + 45m = 225m + 45m = 270m that's only four and a half hours! We were able to overlap the washing and drying phases!
Now, this is the power of pipelining! Of course, you’re still bottlenecked by the longest-running stage, which is washing—a very important fact to remember.
Fun fact: Your CPU is also using pipelining while processing assembly instructions! Check out Instruction pipelining if you are looking for a good starting point.
So, separate machines have higher throughput! This leads me to another important concept: latency, which measures the time to complete a single task (e.g., a round of laundry) and, in both cases, it’s fixed at 2 hours.
Threading patterns
Let me start by refactoring one of the synthetic benchmarks from the first installment, where we processed the image data. To keep things simple, I moved the buffer allocation out of the function.
// Single-threaded version
void ImageTweaker::syntheticBenchmarkBaseline(
std::vector<uint8_t> &pixels, // inout
size_t width = 4032,
size_t height = 3024
)
{
const size_t pitch = 4 * width; // assume 4 bytes per pixel
const size_t numBytes = pitch * height;
assert(pixels.size() == numBytes);
ZoneScoped;
for (size_t retry = 0; retry < 100; ++retry) {
ZoneScopedN("SyntheticTransform2D_Baseline");
for (size_t y = 0; y < height; ++y) { // from top to bottom
for (size_t x = 0; x < pitch; ++x) { // from left to right
const size_t i = y * pitch + x;
pixels[i] = 2 * pixels[i] + 1;
}
}
}
}The knee-jerk reaction would be to split the outer loop into smaller pieces and then run every single one of them on a separate thread, right? This will work, as there are no data dependencies between iterations, making this an embarrassingly parallelizable workload! We can start by offloading every single row to its own dedicated thread.
Initially (and out of laziness), I was tempted to use OpenMP in my examples, as they are supported by all major compilers, but I decided not to overwhelm non-C++ developers. Instead of using preprocessor directives, I’ve rolled out my own function instead.
// First (naive) multi-threaded version
void ImageTweaker::syntheticBenchmarkThreadedRows(
std::vector<uint8_t> &pixels,
size_t width = 4032,
size_t height = 3024
)
{
const size_t pitch = 4 * width; // assume 4 bytes per pixel
const size_t numBytes = pitch * height;
assert(pixels.size() == numBytes);
ZoneScoped;
for (size_t retry = 0; retry < 100; ++retry) {
ZoneScopedN("SyntheticTransform2D_ThreadPerRow");
parallel_for (0, height, [](y) => { // y=0; y <= height
for (size_t x = 0; x < pitch; ++x) {
const size_t i = y * pitch + x;
pixels[i] = 2 * pixels[i] + 1;
}
}, height); // number of threads = number of rows
}
}I tried to stay as close to the original code as possible. Here’s my implementation of parallel_for:
template <typename Func>
void parallel_for(
size_t start, size_t end,
Func body,
size_t numThreads
)
{
assert(start <= end);
const size_t size = end - start;
numThreads = std::min(numThreads, size);
const size_t chunkSize = (size + numThreads - 1) / numThreads;
std::vector<std::thread> threads;
threads.reserve(numThreads);
// Create and run threads (a.k.a. "fork")
for (size_t i = 0; i < numThreads; ++i) {
const size_t chunkStart = i * chunkSize + start;
const size_t chunkEnd = std::min(chunkStart + chunkSize, end);
threads.emplace_back([chunkStart, chunkEnd, &body]() {
for (size_t ci = chunkStart; ci < chunkEnd; ++ci) {
body(ci);
}
});
}
// Wait for all threads to finish (a.k.a. "join")
for (auto& t : threads) {
if (t.joinable())
t.join();
}
}This “pattern” of multithreading, where you create all your threads just before your workload, run it and wait for all the work to finish is called fork-join. It’s not the most efficient one, but must suffice for now. My implementation exposes one additional parameter that we can tweak—the number of threads.
Note that each thread is given exactly 1 unit of work.
This is where I would like to pause, and ask: how many threads should we create? Does it even matter? The worst answer is to say “whatever”, while the simplest would be to process every row in a separate thread (which I did on purpose above). I have done my due diligence and measured the execution time of both the single-threaded baseline version, and the “ThreadPerRow”, here are the results:
Wow, that didn’t work! We threw 3024 threads at this “problem” and we got about 4 times slower?! I did an extra homework for you (as it would help me to make a point a bit later). I tried different amounts of threads, and instead of a boring table, I plotted them on a chart:
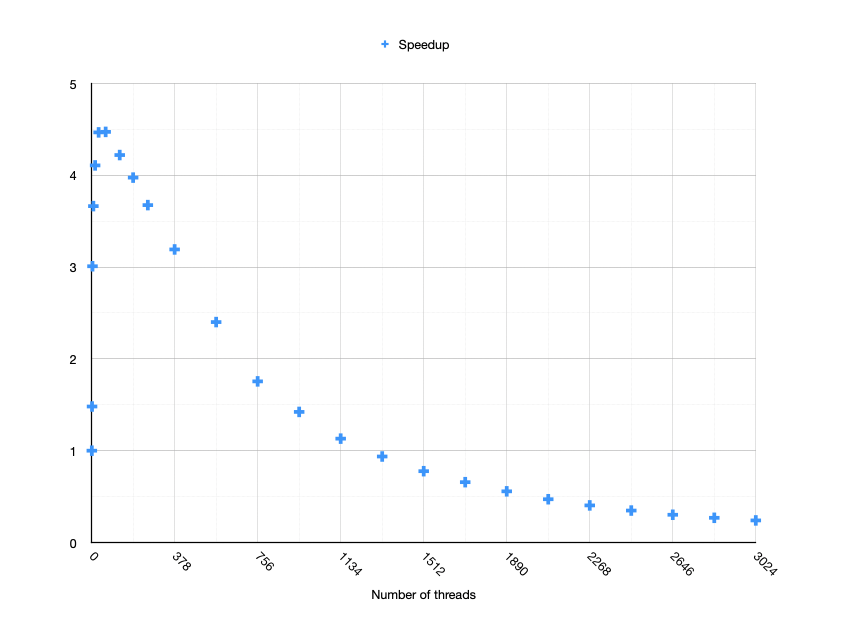
Isn’t it interesting? We should immediately ignore all thread numbers whose Y-value is below 1! Moreover, there seems to be a ceiling set around 4,5 times.
First of all, multithreading rarely scales linearly—we are bound by the number of CPU cores and moreover by the Amdahl’s law, and this is something we might intuitively understand. Adding more people to work on a single problem works only up to some point, and the above plot clearly shows that.
What else can we see? Actually, if we seriously reduce (or at least take the first quarter) the number of threads, the app will run faster! We can also see that our graph peaks somewhere under 200 threads. So I’ve prepared yet another chart (apologies to my math-savvy readers, but I wasn’t able to set a log2 scale in Apple’s Numbers; I’ll continue to use a linear scale in my charts):
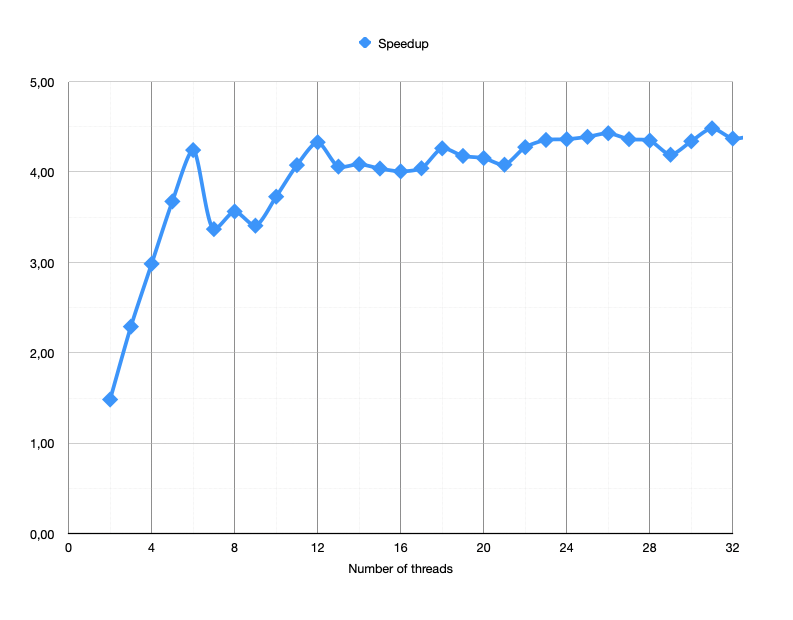
Here’s a bummer: what if I told you that the machine I run those benchmarks on had 8 CPU cores? What happens above is that number is basically oversubscription—we create more threads than can be executed at the same time, and then the operating system has to juggle between them—and this switching has its cost as well. You can edit our last source code and use std::thread::hardware_concurrency() instead of a hardcoded number of threads!
I’ve also mentioned that the fork-join model is not the best—maybe there is an additional batch of work that we can start processing while waiting for the current one to finish. Moreover, creating and destroying threads also takes time. This is something we can actually measure in a couple of different ways. Besides, if the workload gets too small, the cost of creating threads might become higher than doing computation.
Long live the thread!
We should try to amortize the cost of creating threads, ideally by creating our pool of worker threads! We create the optimal number of them ahead of time, and ask them to wait for tasks to execute. Simple right?
On paper—yes. But in practice, this will lead to a work-distribution “problem”. Currently, we ended up splitting our image into “bands”, where the height of a band depends on the number of “hardware threads”. If the image has 3024 rows, then 3024 divided by 8 cores gives a batch of 378 rows. My oversimplified toy example might mask a small issue. In the real-world, our workloads are rarely uniformly sized.
Even ignoring this fact, with similarly sized workloads, some threads might finish earlier than others, and end up waiting for “next batch”. I have a great example that demonstrates this perfectly: queues in shopping malls!
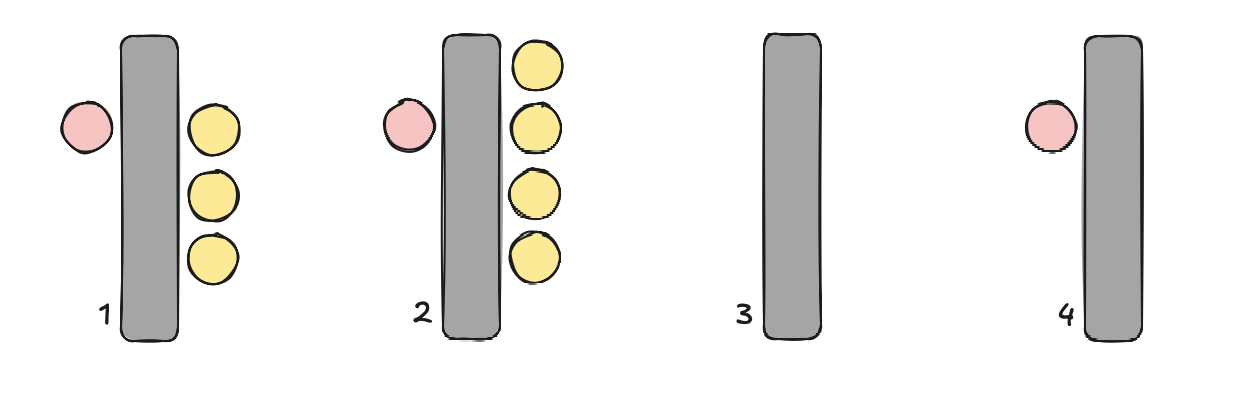
Imagine you finished doing your groceries and are heading towards the counter. The drawing above represents the situation upon your arrival. This particular shop has four counters (gray rectangles are the belts, those are your hardware threads), but only three clerks (red circles, your worker threads) are handling customers (yellow circles). Usually, some customers have just a few items, while others might have the whole shopping cart filled with stuff. Of course, every human is different; therefore, cashiers might also process customers at different speeds. Where would you go?
I’m assuming you would “enqueue” yourself at the fourth counter—that’s what I would do. Asking to open another one would be extremely silly. But this assumes that you have free will. Imagine now that you got hired at this shop (became a blue circle) and you are assigning customers (from the main queue) to individual lanes. How would you do it? What would be your heuristic?
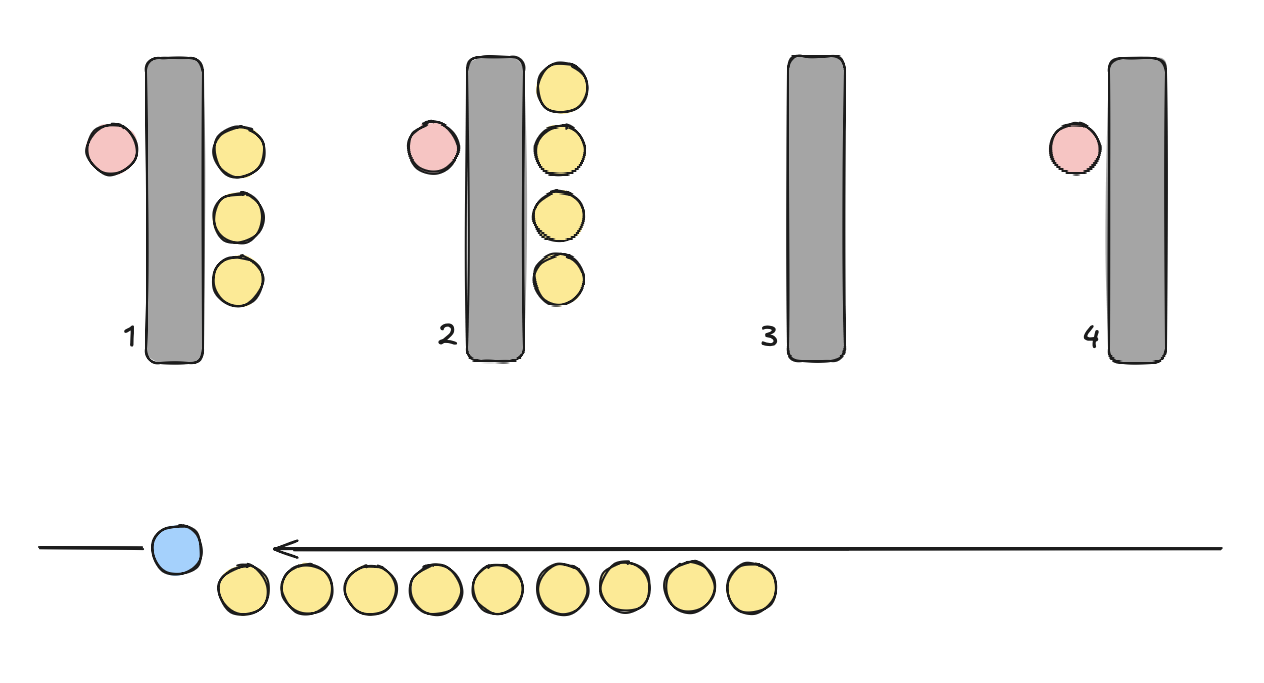
For simplification purposes, we treat all customers the same way, no matter what. We don’t support priority tasks.
The so-called Round-Robin approach would assign customers one-by-one to the next available desk. Hence, if all counters are open, the fourth customer would go to fourth one, the fifth would start from the first, etc. This is a good starting point and kinda what we implemented, but what if every fourth customer has a full shopping cart? They all will end up at the same counter! Hopefully, this particular cashier has really fast hands (shoutout to German cashiers working in Lidl 😄).
If you are a web-developer, the phase “Round-Robin” may sound very familiar to you. It’s, indeed, the same problem that load balancers face.
If you want to avoid responsibility, you can try employing a randomized process. I don’t really remember if this has a proper name, but I would name it “Russian-Roulette scheduling”. You can always try to convince an angry or impatient customer that they just had bad luck. On the positive side, it would be hard to “exploit” such a system, like finding a pattern to assign all “big customers” to the same lane.
Speaking of which, if there is a group of really fast clerks, should they be able to ask for customers to join them? If so, from the main queue or from a different desk? Which one? What if a cash machine breaks? If we do nothing, the customers will wait there “infinitely”. Should they continue waiting or join another queue? If so, which one?
This is where I expose you to different scheduling methods: work requesting and work stealing. Fun fact, some of the hypermarkets we have in Europe employ “buffered” work requesting. I like work-stealing a bit more, when the main queue is empty, the free desks can ask customers from overloaded desks to join them instead. It is a bit more costly, as they have to change conveyor belts (pack and unpack again), but generally it works well.
Just (another) short segue: it might be tempting to allocate your thread pool once, and keep it running for the whole duration of your app. This works extremely well in games and server applications, but we—mobile app developers—should also optimize for battery life! Every app is different, so you may consider implementing a flexible thread pool that scales up and down depending on the workload.
Implementation time
Let’s codify what we discussed above. I’ve drafted a naive scheduler keeping two goals in my head:
- We want to maintain a pool of worker threads, instead of creating and destroying them all the time.
- There is a global task queue, and workers should be able to grab tasks from there. This would finally allow us to break the limit that a thread was processing only 1 batch.
class WorkSharingPool {
public:
using Task = std::function<void()>;
WorkSharingPool(size_t numThreads = std::thread::hardware_concurrency())
: m_isQuitting(false)
, m_syncRequested(false)
{
ZoneScoped;
// Create worker threads that will run `workOnTasks()`
m_workers.reserve(numThreads);
for (size_t i = 1; i <= numThreads; ++i) {
m_workers.emplace_back([this, i] { workOnTasks(i); });
}
}
~WorkSharingPool()
{
quit();
};
void add(Task&& task)
{
ZoneScoped;
std::lock_guard<LockableBase(std::mutex)> lock(m_queueLock);
m_mainQueue.emplace(task);
m_cv.notify_all();
}
void waitUntilFinished()
{
ZoneScoped;
m_syncRequested.store(true);
m_cv.notify_all();
{
std::unique_lock<LockableBase(std::mutex)> lock(m_queueLock);
m_cv.wait(lock, [this] { return m_isQuitting.load() || (m_mainQueue.empty() && m_idleWorkers == poolSize()); });
}
}
void quit()
{
m_isQuitting.store(true);
m_syncRequested.store(true);
m_cv.notify_all();
// Wait for the threads to finish
for (std::thread &t : m_workers) {
if (t.joinable())
t.join();
}
}
inline size_t poolSize() const { return m_workers.size(); }
private:
std::vector<std::thread> m_workers; // implements the clerks (red circles)
TracyLockable(std::mutex, m_queueLock); // to avoid race-conditions on the main queue
std::condition_variable_any m_cv; // "wake up" a sleeping worker when tasks get updated
std::queue<Task> m_mainQueue; // our customers waiting for processing
std::atomic<bool> m_isQuitting; // whether threads should keep working or quit
std::atomic<bool> m_syncRequested; // whether we want to synchronize with our workers
std::atomic<size_t> m_idleWorkers;
std::optional<Task> tryGetTask(bool &isIdling)
{
ZoneScoped;
std::optional<Task> task;
// Wait for tasks to be available.
// No need to constantly yell "next please" to an empty space...
std::unique_lock<LockableBase(std::mutex)> lock(m_queueLock);
m_cv.wait(lock, [this] { return m_syncRequested.load() || !m_mainQueue.empty(); });
// Pop the task from the global queue
if (!m_mainQueue.empty()) {
task = std::move(m_mainQueue.front());
m_mainQueue.pop();
if (isIdling) {
--m_idleWorkers;
isIdling = false;
}
} else if (!isIdling) {
++m_idleWorkers;
isIdling = true;
m_cv.notify_one();
}
return task;
}
void workOnTasks(size_t workerIndex)
{
#if TRACY_ENABLE
ZoneScoped;
char name[16];
snprintf(name, sizeof name, "Worker #%zu", workerIndex);
tracy::SetThreadName(name);
#endif
bool isIdling = false;
while (m_isQuitting.load() == false) {
std::optional<Task> task = tryGetTask(isIdling);
// Execute the task, then rinse, repeat
if (task.has_value()) {
ZoneScopedN("Execute task");
(*task)();
}
}
}
};Then, I overloaded my parallel_for() function to make it work with this new scheduler:
template <typename Func>
void parallel_for(
size_t start, size_t end,
Func body,
WorkSharingPool &pool
)
{
assert(start <= end);
const size_t size = end - start;
const numChunks = pool.poolSize();
const size_t chunkSize = (size + numChunks - 1) / numChunks;
// Distribute workload as evenly as possible
for (size_t i = 0; i < numChunks; ++i) {
const size_t chunkStart = i * chunkSize + start;
const size_t chunkEnd = std::min(chunkStart + chunkSize, end);
pool.add([chunkStart, chunkEnd, &body]() {
for (size_t ci = chunkStart; ci < chunkEnd; ++ci) {
body(ci);
}
});
}
// Wait for all threads to finish (a.k.a. "join")
pool.waitUntilFinished();
}and finally our benchmarking function:
// Second (naive) multi-threaded version
void syntheticBenchmarkWorkSharedBands(
std::vector<uint8_t> &pixels,
size_t width = 4032,
size_t height = 3024
)
{
const size_t pitch = 4 * width; // assume 4 bytes per pixel
const size_t numBytes = pitch * height;
assert(pixels.size() == numBytes);
// Create the thread pool
const size_t numWorkers = std::thread::hardware_concurrency();
WorkSharingPool pool(numWorkers);
ZoneScoped;
for (size_t retry = 0; retry < 100; ++retry) {
ZoneScopedN("SyntheticTransform2D_WorkSharedBands");
parallel_for(0, height, [pitch, &pixels](size_t y) { // y=0; y <= height
for (size_t x = 0; x < pitch; ++x) {
const size_t i = y * pitch + x;
pixels[i] = 2 * pixels[i] + 1;
}
}, pool);
}
}How did it perform? Oh boy, look at that chart:
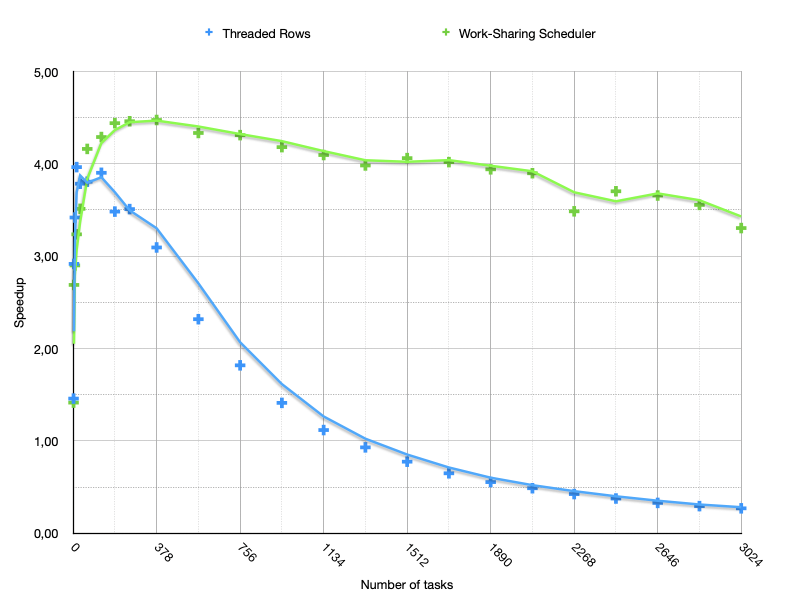
Basically, we are doing way, way better no matter the number of tasks. Yes— tasks— as our Work-Sharing scheduler above maintains a thread-pool of fixed size (eight threads on my MacBook), while our first “Threaded Rows” implementation had a strict one job = one thread relation. It’s a good idea to contemplate this performance gap!
Can’t touch this (lock)
Don’t get too excited, tho… We just have started and we haven’t really used Tracy yet.
At the beginning of this article, I mentioned locks, right? Concurrency really hates locks (on the hot path), and it doesn’t mean more locks cause more problems. If you skimmed over my scheduler carefully enough, you might have seen that I’ve used some Tracy macros, right? So Tracy, can you help me?
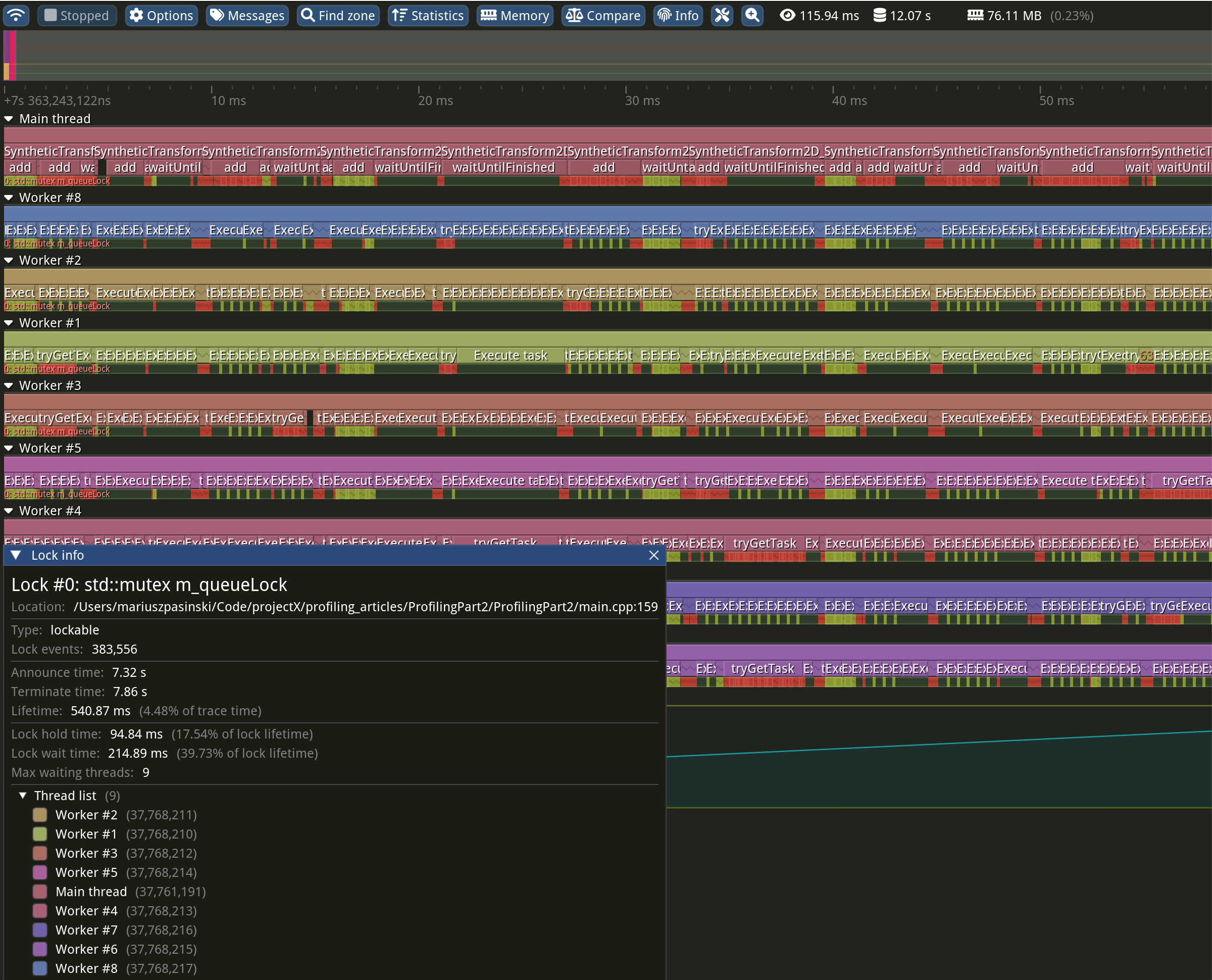
Within each “thread line”, under the flamegraph, you can see the locks that the thread was taking (yellow) or waiting on (red). Unfortunately (but as expected), I see a lot of red, which is a very bad sign. This dreaded phenomenon is called Thread Contention. In the “Lock info” window on the bottom left you can even read: “Lock hold time: 94.86ms” and “Lock wait time: 214.89ms“! Yes, we are literally waiting longer than “popping” the task would take! More than twice!
This is why I’ve instrumented theadd()andtryGetTask()methods, as well as the "Execute task" zone within the worker’s loop. This allows me to demonstrate thread contention visually and can help estimating the scale of the issue. As we want to maximize throughput, we should maximize the time that workers spend executing tasks and ideally minimize the time spent intryGetTask().
If I had to put this into my shopping metaphor, image that each time the clerk finishes processing a customer, they have to call you over the phone and ask for another customer. But you can talk only with one clerk at a time; others will be waiting until you pick up their phone. And this happens all the time, after each single customer is being processed—yikes!
We can try to reuse one of our tricks that worked before, namely, we can try to amortize the cost of “acquiring” customers by asking for a “batch” of them. The conveyor belt is long, and we can try to enqueue say 6 of them (btw, I just rolled a die to get that number). We can add a small per-thread random number to it. While this is a good idea and it promotes data locality, it will only hide the problem under the carpet. Can we do something regarding the locks?
Clearly defined roles
What is the memory access pattern for our queue, and who plays which role in the system? “Chaotic” might be one answer, but I’m more interested in identifying the producer and consumer roles. For now, only the main thread is submitting tasks to our scheduler. Therefore, the main thread is the sole producer in the system. As for who is consuming those tasks, it's all of the worker threads, so we are dealing with a single-producer, multiple-consumer (SPMC) setup.
Without going too deep into technicalities (though I highly recommend reading Dmitry Vyukov's blog post for more on the subject), there are many lock-free and wait-free SPMC queues we can use (or implement ourselves). Maybe queue is not the most precise word, as we are interested in double-ended queues to be precise. Those “beasts” have no need to synchronize producers and consumers, each end of the queue is “independent”.
For this article, I picked a classic one: Chase-Lev SPMC double-ended queue from the “Dynamic Circular Work-Stealing Deque” paper (I’ve warned you that I’m biased towards work-stealing). Members in this family of queues have three major operations: push_back() and pop_back() dedicated for the owner, and steal() for everybody else. As the name suggests, the owner will observe a LIFO order, while the stealer FIFO.
Do we want to replace the main queue with such “deque”? Perhaps we should think about removing the main queue altogether? Is this even possible and how could this reduce thread contention?
Wait, that’s it?
I’m afraid I’ll cut this article here. I would like to give you a bit time to digest all the above, play around and maybe think of ways to reduce thread contention. In the next article in this series, we will continue with work-stealing and maybe I’ll show you how adding more fiber will increase throughput 😄
In this article we learned a lot about techniques for making your programs benefit from multiple threads of execution. I’ve left you with some handy questions, here they are again:
- Are we using the threads effectively?
- Is the work evenly distributed across threads?
- Which threads are waiting on locks?
- How does context switching affect throughput?
And perhaps now you can see how most of them are important, and maybe you already have ideas on how to reliably measure and visualize them. An instrumented profiler will be an invaluable tool that will help you find answers to those burning questions, and Tracy is really a great tool. I’ve barely scratched the surface of thread contention (and how Tracy visualizes it) but you will have to wait for the next installment, where we will continue our “Hypothesis-Oriented programming”—it’s gonna be worth the wait 🙂 In the meantime, I invite you to experiment with work distribution and load-balancing yourself!



Learn more about Performance
Here's everything we published recently on this topic.





















